How does MLOps handle data
Data is the backbone of machine learning, so ensuring that it’s clean and accurate is essential. Using best practices for data preprocessing and cleaning helps organizations avoid data corruption. Using tools for data preprocessing and cleaning is also a good way to ensure that ML models can be trained quickly on new or diverse data sets.
mlops course are a common standard in data engineering and data management. These pipelines include data extractions, transformations and loads. These pipelines can be a great way to keep track of the different steps involved in a data pipeline, and help teams to streamline their processes.
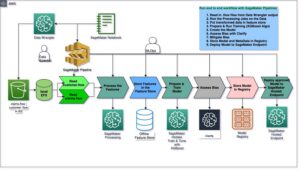
Similarly, MLOps uses a set of processes to automate the development and deployment of machine learning models. These processes can help to reduce the errors that can occur during algorithm development and help engineers to focus on the core of algorithm development, enabling them to create more reliable applications.
How does MLOps handle data preprocessing and cleaning?
This is similar to the way that DevOps has been used for years to automate software development and integrate, test, and deploy code, easing the workload for developers. MLOps brings this same best practices to ML model development, making the entire process more efficient, enabling experts to focus on building high-quality algorithms and creating real business value.
mlops tutorial for beginner aims to unify all the various phases of data collection, preprocessing, training, evaluation, and deployment in a single process that teams can maintain. This communication and collaboration between DevOps, ITOps, data engineers, and data science teams can help to ensure that production-ready machine learning models are developed and maintained in a consistent way across all organizations.
The first step in MLOps is to collect all the data needed to train a machine learning model. This is done by deploying a data ingestion pipeline that can ingest data from multiple sources and formats, such as from a central database or from various data lakes.
Next, the data needs to be transformed into a format that can be used to train a machine learning model. This can be done by either using a dedicated ML data management platform or an open source tool for data processing.
While most ML models are initially trained during the development phase, it is important to continuously retrain the model as new data is gathered and processed. This allows the model to improve over time and adapt to the changing environment, a process that can be difficult if models are manually trained.
ML model testing is also critical in order to validate the quality of an ML model before it is deployed into production. This should be done in a statistical way to ensure that models are consistently performing well and that the results can be reproduced.
Many organizations are already using a variety of tools for ML model and data testing, but many organizations are still struggling with the reproducibility of ML experiments. This is a big challenge in the ML and AI industry, and one that is being solved by a number of tools that allow for a better approach to testing.